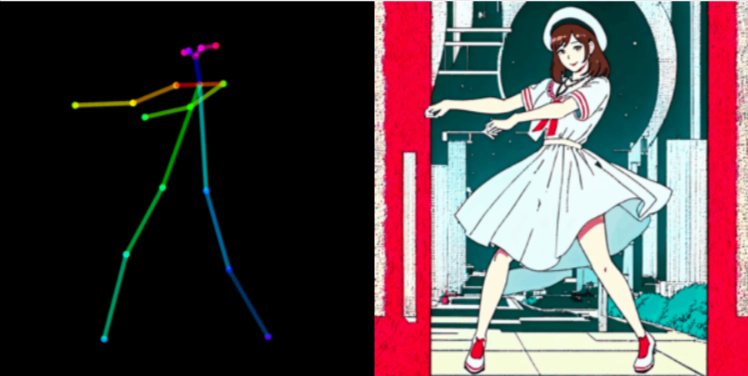
ComfyUIでポーズや衣装を想定したもの(近いもの)にする方法。Geminiが教えてくれました。この回答にたどり着くまで結構大変でしたので、だれかの役に立てば。
ご質問の**「ポーズや衣装を変える」**には、img2imgよりも、もっと強力で楽しいツールがあります。
### 🎨 ポーズと衣装を変える最強のツール:ControlNet
あなたがやりたいこと(元の絵の画風は保ったまま、ポーズや衣装だけ変える)を実現する技術を**「ControlNet(コントロールネット)」**と呼びます。
これは、ComfyUIが最も得意とする分野です!
ControlNetは、AIに対して「この棒人間のポーズを**絶対に**真似してね」と命令できる機能です。
ComfyUIでこれを行うには、**LoRAのワークフローに、ControlNetのノードを追加**します。
—
### 🛠️ ステップ1:ControlNetモデルの準備(Stability Matrix)
まず、ComfyUIが「ポーズを読み取る」ためのAIモデルをダウンロードする必要があります。Stability Matrixなら簡単です。
1. Stability Matrixを起動します。
2. 左のメニューバーにある**「Model Browser」**(地球儀のようなアイコン)をクリックします。
3. 上の検索バーで**control_v11p_sd15_openpose**と検索します。
4. control_v11p_sd15_openpose.safetensors というファイルが見つかるので、[Download]ボタンを押します。
* これが「ポーズ」を専門に扱うControlNetモデルです。
* Stability Matrixが自動で Data\Models\ControlNet フォルダに保存してくれます。
※これらがまとめたパックのConfyroll Studioをダウンロードしました、ダウンロードサイズが大きいと自動ではできないので手動でやりました
### 🛠️ ステップ2:ControlNetノードの準備(Stability Matrix)
次に、ComfyUI内で「ポーズを抽出する」ためのカスタムノード(機能拡張)を入れます。
1. Stability Matrixの左側メニュー「パッケージ」(🚀アイコン)を選びます。
2. ComfyUI の欄にある「…」メニューをクリックし、**「Manage Package」**(パッケージを管理)を選びます。
3. **「Install Custom Nodes」**(カスタムノードをインストール)ボタンをクリックします。
4. 検索バーで**ComfyUI's ControlNet Auxiliary Preprocessors**という名前のノードを探し、[Install]します。
5. インストールが完了したら、Stability Matrixに戻り、ComfyUIを**再起動(Launch)**します。
### 🛠️ ステップ3:ポーズ画像の準備
AIに真似させたい「ポーズの元画像」を準備します。これは**どんな画像でも構いません**。
*「棒人間(スティックフィギュア)」の画像

* ポーズの参考になる別の写真やイラスト
* (ComfyUIのLoadImageノードで、この元画像をアップロードします)
### 🛠️ ステップ4:ComfyUIワークフローの構築 (LoRA + ControlNet)
いよいよ配線です!先ほどのLoRAワークフロー(Load LoRAまで繋いだ状態)に、以下のノードを追加していきます。
1. **Load Checkpoint** → **Load LoRA** → …(これは前回と同じ)
2. **CLIPTextEncode (Positive)**(ポジティブプロンプト)
3. **CLIPTextEncode (Negative)**(ネガティブプロンプト)
4. **空の潜在画像**(txt2imgの時と同じ、空の画像。サイズは512×768などでOK)(潜在→空の潜在画像)
**【ここからがControlNetの追加部分】**
5. **画像を読み込む** ノードを追加(画像→画像を読み込む)
* ここに、ステップ2で用意した**「真似させたいポーズの元画像」**をアップロードします。
6. **OpenPose Pose** ノードを追加(ControlNet PreProsesseors→
* 画像を読み込む の 画像 出力を、このノードの image 入力に繋ぎます。
* (これで、AIが元画像から「棒人間」を自動で抽出します)
7. **ControlNet Modelを読み込む** ノードを追加(ロード→ControlNet Modelを読み込む)
* control_net_name で、ステップ1でDLした **control_v11p_sd15_openpose.safetensors** を選びます。
8. **CR Apply ControlNet** ノードを追加 (Confyroll Studio→ ControlNet→ CR Apply ControlNet)
* このノードに、以下を**3つ**繋ぎます。
* conditioning ← CLIPTextEncode (Positive) の CONDITIONING 出力
* control_net ← Load ControlNet Model の CONTROL_NET 出力
* image ← OpenPose Pose の IMAGE 出力
※画像→OpenPose Editorのノードも追加(手だけ、顔だけ、など固定するパーツを選べるノード)
**【最後の仕上げ】**
9. **KSampler** ノード(AIが絵を描くノード)
* model ← Load LoRA の MODEL 出力
* positive ← **CR Apply ControlNet** の 条件付け 出力(**重要!**)
* negative ← CLIPTextEncode (Negative) の CONDITIONING 出力
* latent_image ← EmptyLatentImage の LATENT 出力
10. KSampler の LATENT 出力を VAEDecode → Save Image に繋げば完成です!
—
### 🎨 ステップ5:プロンプトの実行
* CLIPTextEncode (Positive) ノードに、**LoRAの呪文** (〇〇) と、**新しい衣装の指示**(例: 〇〇, (blue dress:1.3), standing)を入力します。
* KSampler の **ノイズ除去 は 1.0** に設定します。(元画像がないので、100%新しく描かせます)
* **実行するボタン**
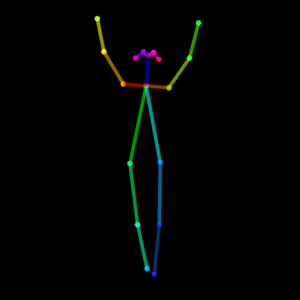

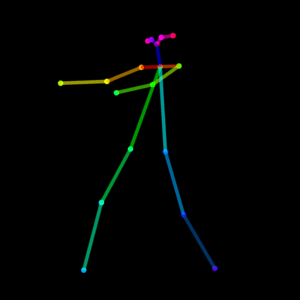



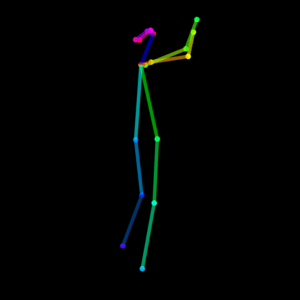

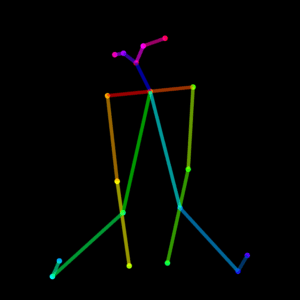

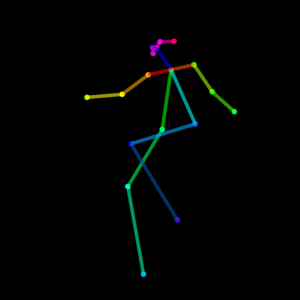

さすがに足を組むのはまだうまく描けませんが、すごいですね、AI。





この記事へのコメントはありません。